

Partielle Automatisierung der Arealstatistik der Boden mit Hilfe von Informationen der räumlich-zeitlichen Nachbarn

Eine der Aufgaben des Bundesamts für Statistik (BFS) ist die Erstellung der Arealstatistik, eines Instruments, mit dem gemessen werden kann, ob die Bodenbedeckung und -nutzung zu einem bestimmten Zeitpunkt und im Laufe der Zeit mit den Zielen der Raumentwicklung übereinstimmt. Für weitere Informationen verweisen wir den Leser auf diese Seite. In Bezug auf dieses Dokument sei folgender Auszug zu zitieren: 'Die Interpretation der Bodennutzung und -bedeckung erfolgt für feste Stichprobenpunkte, die in einem Raster von 100 m x 100 m über die Luftbilder gelegt sind'. Es sollte auch darauf hingewiesen werden, dass die Interpretation jedes dieser Punkte die Zuweisung einer Klasse (von 27) in Bezug auf die Nutzung und einer Klasse (von 46) in Bezug auf die Bedeckung umfasst.

Seit 2022 verwendet das Bundesamt für Statistik eine innovative, durch künstliche Intelligenz (KI) angetriebene IT-Lösung, die den Prozess der Klassifizierung der festen Stichprobenpunkte teilweise automatisiert und damit die Aktualisierungszyklen verkürzt. Mehrere Indikatoren werden von der KI als Input verwendet. Das BFS hat das STDL beauftragt zu untersuchen, ob für jeden Stichprobenpunkt ein en-ter Indikator verwendet werden sollte, der auf der Grundlage früherer Klassifizierungen ('zeitliche Nachbarn') desselben Punktes und seiner unmittelbaren Nachbarn ('räumliche Nachbarn') gebildet wäre. Dieses Projekt wird feststellen, ob die 'zeitlich-räumlichen Nachbarn' Informationen enthalten, die für die Klassifizierung und/oder die Vorhersage einer wahrscheinlichen Veränderung im Vergleich zur vorherigen Klassifizierung nützlich sind.
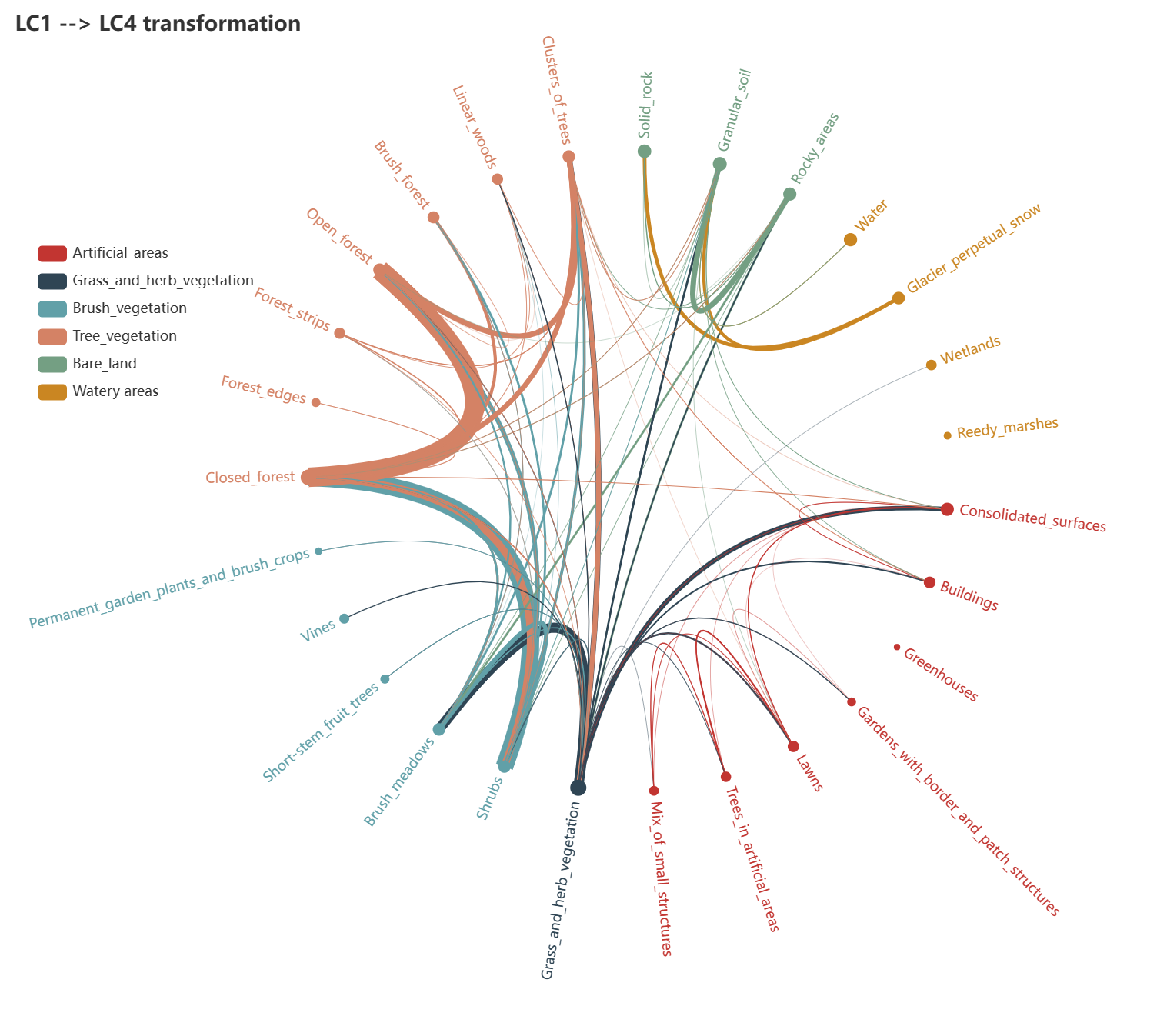
Das Projekt erforschte den internen Verwandlungsmechanismus der Schweizer Bodenstatistik aus der Sicht der Datenanalyse und baute einen Prototyp, der die Erkennung von Veränderungen für eine Kachel in der nächsten Klassifizierung durchführt. Wir haben mehrere neue Techniken des maschinellen Lernens angewandt, um die Interpretationsarbeit zu beschleunigen, insbesondere mit Deep-Learning-Algorithmen wie dem "Fully Connected Network" und dem "Convolutional Recurrent Neural Network". Durch die Verwendung von zeitlichen und räumlichen Daten aus der Nachbarschaft verbessert unser Prototyp die Leistung um ca. 15,8 % im Vergleich zur Baseline (6 % in Metrik). Dank des entworfenen Arbeitsablaufs wird das Projekt 30-40 % des geschätzten Arbeitsaufwands für das Interpretieren, der sich aus den Forschungsergebnissen ergibt, einsparen.
Der Quellcode ist auf Github verfügbar.
Für weitere technische Details besuche die technische Website des STDL.